この記事でわかること
- 母集団と標本の違い
- 母平均と標本平均の違い
- 標本分散と不偏分散の違い
- マーケティング実務での活用シーン
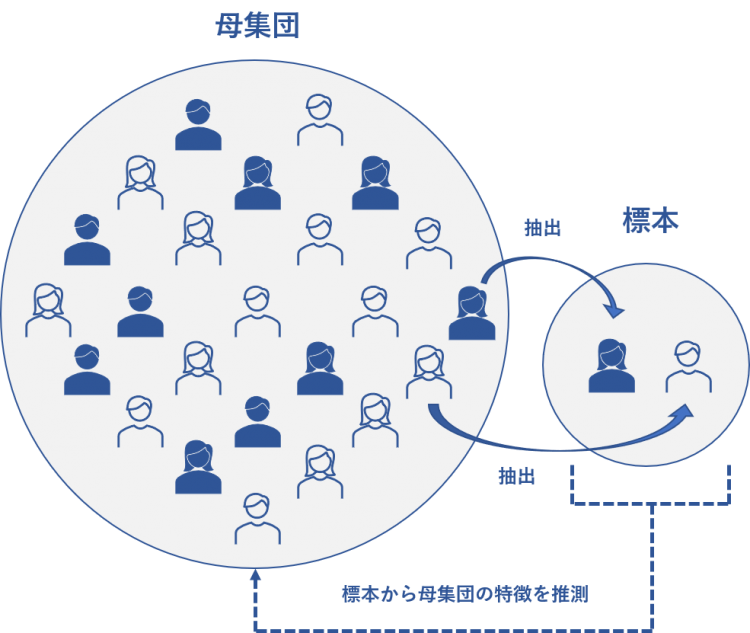
母集団と標本の違い
統計学の基本として、まず「母集団」と「標本」の違いを理解しましょう。
母集団とは、調査・分析の対象となるすべてのデータの集まりです。
標本とは、母集団から一部を抽出したデータの集まりです。
たとえば「日本の20代女性の平均年収を調べたい」という場合、日本の20代女性全員(数百万人)が母集団です。ところが全員に調査することは現実的ではないため、1,000人を無作為に抽出して調査します。この1,000人が標本です。
母平均(ぼへいきん)とは
母平均(μ:ミュー)とは、母集団全体の平均値です。
たとえば、日本の20代女性全員の年収を合計して人数で割った値が母平均です。
母平均の公式:
- xi:母集団の各データ
- N:母集団のデータ数
母集団が大きすぎる場合、母平均を直接計算することはほぼ不可能です。そこで標本から推定します。
標本平均とは
標本平均(x̄:エックスバー)とは、抽出した標本の平均値です。
-
- xi:標本の各データ
- n:標本のデータ数
先ほどの例で、抽出した1,000人の年収の平均が400万円だったとします。この400万円が標本平均です。
母平均(日本の20代女性全員の平均)とは必ずしも一致しませんが、適切に標本を抽出すれば、母平均に近い値になります。
母平均と標本平均の違いまとめ
| 項目 | 母平均(μ) | 標本平均(x̄) |
|---|---|---|
| 対象 | 母集団全体 | 抽出した標本 |
| 計算可能か | 通常は困難 | 計算可能 |
| 使い方 | 推定の目標値 | 母平均の推定値として使う |
標本分散と不偏分散の違い
分散とは「データのばらつき」を表す指標です。分散には2種類あります。
標本分散(s²)
標本のばらつきを表す分散です。分母が n(標本数)です。
不偏分散(ふへんぶんさん)(u²)
母集団の分散を推定するための分散です。分母が n-1 になります。
標本のばらつきを表す分散です。分母が n(標本数)です。
なぜ不偏分散の分母はn-1なのか?
標本は母集団の一部を抜き出したものなので、標本の分散は母集団の分散より小さくなる傾向(偏り)があります。分母をnではなくn-1にすることで、この偏りを補正し、母集団の分散をより正確に推定できます。
この補正のため、不偏分散は「N-1の分散」とも呼ばれます。
標本分散と不偏分散の違いまとめ
| 項目 | 標本分散(s²) | 不偏分散(u²) |
|---|---|---|
| 分母 | n | n-1 |
| 意味 | 標本のばらつきを表す | 母集団の分散を推定する |
| 使い方 | 標本そのものの分析 | 母集団の分散を推定したいとき |
マーケティング実務での活用例
「母平均と標本平均」の考え方は、マーケティングのデータ分析でも頻繁に使います。
① アンケート調査の結果を読むとき
自社サービスの顧客満足度調査を500人に実施した場合、この500人が標本、顧客全体が母集団です。「満足度平均4.2点」はあくまで標本平均であり、顧客全体の満足度(母平均)に近いと推定できますが、イコールではありません。
→ サンプル数が少ないほど誤差が大きくなるため、信頼性の高い結論を出すにはサンプル数の設計が重要です。
② A/Bテストの結果を判断するとき
LP(ランディングページ)のA/Bテストで、Aのコンバージョン率3.2%、Bが3.8%だったとします。この差が統計的に有意かどうかを判断するには、標本平均の差の検定が必要です。
「Bが良さそう」という直感だけで判断せず、サンプル数が十分かどうかを確認することが重要です。
③ 広告の効果測定
特定のターゲット層に広告を配信して得られたCTRは、その配信ターゲット全員に配信したときのCTR(母平均)の推定値に過ぎません。配信ボリュームが少ない段階での数値は信頼区間が広く、判断を誤るリスクがあります。
まとめ
| 用語 | 定義 |
|---|---|
| 母集団 | 調査対象となるすべてのデータの集まり |
| 標本 | 母集団から抽出した一部のデータ |
| 母平均(μ) | 母集団全体の平均。通常は直接計算できない |
| 標本平均(x̄) | 標本の平均。母平均の推定値として使う |
| 標本分散(s²) | 標本のばらつきを表す(分母:n) |
| 不偏分散(u²) | 母集団の分散を推定する(分母:n-1) |
データに基づいたマーケティング意思決定を行うために、これらの基本概念をしっかり押さえておきましょう。
データを活かしたマーケティング支援はデジマールへ
デジマールでは、GA4・広告データ・CRMデータなどを統合したデータドリブンなマーケティング支援を提供しています。「データの読み方はわかったが、実際の施策に落とし込めない」という方は、ぜひご相談ください。
著者情報

